I’m too much of an efficient markets guy for that title to be entirely serious but today I’ve seen two interesting graphs and read one really deep blog post that are making me think. Here is graph 1:
If you calculate a price/earnings ratio using annual data, then in a dismal economic year like 2008 when profits are very low, the P/E ratio will spike dramatically. To avoid these somewhat meaningless short-term spikes, the Shiller P/E ratio looks the current price of stocks divided by the average profit levels over the previous 10 years, so that it is less influenced by economic conditions this year.
The Shiller P/E is now 24.8. As the figure shows, it is higher than at any time except the peak of the dot-com boom and its aftermath, and Black Tuesday back in 1929 at the front edge of the Great Depression. In other words, when the P/E ratio has reached this level in the past, sometimes it has gone still higher (as in the dot-com boom), but over the last 130 years it has then always fallen back.

The point here is that, using the price to the 10-year average profit, the stock market looks massively overvalued from a historical perspective. That post also points us to what I’ll call the Hussman post, which has a fascinating discussion on the bear case and follows up with an even better graph that takes the first one and shows (in the red line) that previous overvaluations meant horrible stock returns and vice versa.

I don’t get it. We’ve just had a lost decade where the valuation never ‘corrected’ to the levels seen between ’72 and ’90 and now we’re climbing again? Hussman also has this to say:
On careful analysis, however, the clearest and most immediate event that ended the banking crisis was not monetary policy, but the abandonment of mark-to-market accounting by the Financial Accounting Standards Board on March 16, 2009, in response to Congressional pressure by the House Committee on Financial Services on March 12, 2009. The change to the accounting rule FAS 157 removed the risk of widespread bank insolvency by eliminating the need for banks to make their losses transparent. No mark-to-market losses, no need for added capital, no need for regulatory intervention, receivership, or even bailouts.
I didn’t even know that. Anyway, here’s the next graph:

Suddenly everyone got wealthier? Price increases do ‘happen’, I guess. But why?
Back to the Hussman post for this quote:
The predictable contraction in corporate profit margins will certainly contribute, but remember that changes in corporate profits typically follow changes in combined government and household savings with a lag of 4-6 quarters, and most of the recent shift in combined savings has only occurred since the third quarter of 2012.
And now we’re at the point where I realize why I’m so lost. I don’t understand P/E ratios but I do understand profits and can see why lower consumption levels probably do mean lower profits in the short term, particularly since those higher savings levels are probably chipping away at big debts. Let’s just take that one at face value or now.
What irritates me is that those charts above tell me that I should want to live in an era with low P/E ratios. Do I?
One more chart, graphing annual corporate earnings (source):
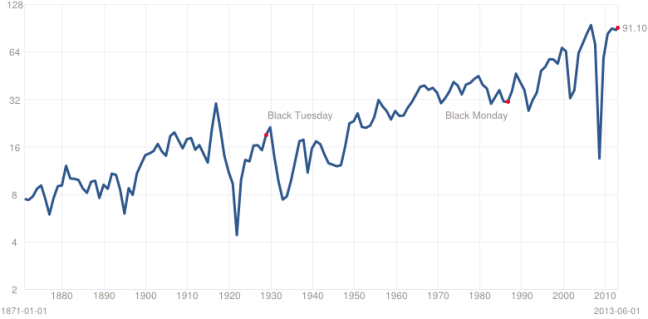
One thing you might notice about the 80s is that that corporate earnings curve is basically totally flat. Does that sound as appealing to you? Your employer not growing?
And what is the point of the 10-year p/e, anyway? Why 10 years? Looking back at that graph of the 80s at the top, showing the 10-year return being the inverse of the valuation level, selling 10 years after the bottom of a market normally puts you square into the top of another market. And the longer those ‘tops’ last (in this case 10 years) the more ‘people’ who bought into those prolonged ‘bottoms’ sell out.
There could be a lot of bias in that 10-year measurement.
So here’s where I am:
- I don’t understand why market valuations grew so much at the end of the 90s. I’m not afraid to climb into my armchair and say I like to think that the baby boomers had something to do with it. Could also be the great stagnation biting down since nonproductive investment defines ‘bubbles’.
- I don’t understand why corporate profits were stagnant in the 80s, grew in the 90s and have been stagnant in the 2000s. Great stagnation?
- I don’t understand why nobody bothers to talk about profits when analyzing the stock market as a whole. Isn’t that the point of all this?
- I don’t understand what monetary policy has to do with any of this.
- I definitely don’t understand what any of this means for investing. Hussman says stocks and long term treasuries are about roughly the same bet at the moment. A common prediction.
So, once again, I have seen some really neat stuff on investing and come away with nothing. How do people do this for a living?


