The question that I don’t have a really good feel for is to what degree the housing market is a canary or millstone. Being only 5% of the economy, one is of course inclined to think of it as a canary.
But here’s the thing: Residential construction companies employ a lot of relatively casual labor. A lot of unskilled labor. A lot of the kind of labor that is, RIGHT NOW, unemployed.
The question then is what the marginal impact of a decline in the housing market might be. One thing’s for sure, anyway. That market is completely effed right now:

In New York we’re noticing some serious signs of the residential and commercial real estate markets recovering (our rent is going up and our expanding office is having some trouble finding a home).
One can take this to mean different things. One interpretation is that there is some serious regional variation contained in these graphs, which appears to have some weight
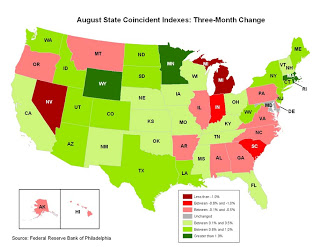
Another possibility is that I don’t know what I think I know because most data is actually just BS.
The problem with new Keynesian economists is that they believe the government data for inflation, real wages, etc, actually measures the theoretical concepts that the model tries to address. But they don’t. Even NGDP is far from perfect, but at least it’s not as distorted as the CPI.
That’s Scott Sumner defending his use of NGDP because it’s the least BS stat out there. I’m heavily persuaded by this kind of argument. A little while ago, I posted something similar to this and actually got into a comment discussion, which is a rather novel thing for me here.
I feel like educated folks tend to make decisions with the part of their brains they trained in school, the part that’s wired for analysis on a given dataset and coming up with The Right Answer is the challenge.
Big contrast to real life. If you had described my job to me when I was a student, I’d imagine myself slogging through difficult math and trying to figure out how to optimally process a dataset. No so. In fact, I’m not sure I’d really want that job or be anywhere near as good at it as I feel I am at this one.
I actually spend about 75% of my time trying to figure out whether this steaming datapile is in ANY way useful. The analytical part is usually pretty straightforward. It has to be. Heck, the rest of my job is trying to shoehorn this datapile into an analysis everyone can understand instantly.
Clients are distracted, busy people and they’d say my work is important but they are often juggling a lot. My complexity test, therefore, goes like this: can this analysis be explained to a child?
And that’s as it should be. Fancy models have their place, but only when used to support conventional wisdom and gut instinct. Counter-intuitive, Complex and Useful: pick two.
I often get the feeling that macroeconomics in particular is a bit too counter-intuitive for its own good. Practitioners get wrapped up in their models and don’t spend quite enough time understanding exactly what is and is not BS. As a result, they have very weak intuition. I suspect they’d be pretty freaked out if they went down to the sausage factory and had a look.






{kind=link}