Here is another look at what’s going on with those peskily quick neutrinos.
The following is the most simple and powerful statistics lesson you’ll get today:

and here:

Here is another look at what’s going on with those peskily quick neutrinos.
The following is the most simple and powerful statistics lesson you’ll get today:
and here:
THE most constant pain in my ass is getting equivalent datasets in radically different formats. Every single insurance company records the same friggen data in different ways.
And if that wasn’t enough, whoever downloads this data then gets their grubby little paws all over it (usually mannually effing around with rows and columns in excel… [vomit]) before sending it to me.
I want machine data, I do NOT want people data. It is infuriatingly complicated cleaning up these datapiles and would all be better if they’d just give me access to their machines.
I’m reminded of the Matrix.
Loving the Sector & Sovereign Blog.
One of my most enduring frustrations with the insurance industry is that there is this bizarre cycle:

For those that don’t want to read about this graph: the industry loses money when the lines cross the horizontal blue line.
This insurance cycle is somewhat related to the business cycle, but the relationship isn’t terribly strong. What the hell is going on then? Some of it is pricing, where rates are cut. But S&S suggest that this masks a shadowy increase in exposure, by way of loosening terms and conditions (T&C) [emphasis in original]:
Rather, we think price declines are concurrent with deteriorating policy term & conditions, and that this is the main source of loss trend deterioration. In other words, we think the industry contributes more to its own loss trend experience than external inflation
We test this theory using loss trend data for work comp, available from the NCCI. We model frequency, medical severity, and indemnity severity separately as well as together. In every case, pricing from 3 years ago matters more than any possible macroeconomic factor.
Now that’s a cool idea. And probably a correct one.
A problem, of course, is that it’s not a terribly useful idea, from the perspective of making money. The market stays stupid for longer than you can stay liquid, after all.
And this isn’t directly observable or measurable, even for reinsurers. People will conceal this kind of T&C deterioration and, because of its lag, the villains have good reason to believe they will get away with it in advance. And for good reason: everyone else in history has.
I’m still ruminating on my critique of S&S’s compelling but (I believe) flawed theory of supply and demand in the insurance market.
Jialang Wang via MR:
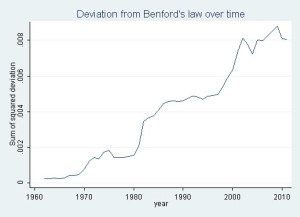
Benford’s law, also called the first-digit law, states that in lists of numbers from many (but not all) real-life sources of data, the leading digit is distributed in a specific, non-uniform way. According to this law, the first digit is 1 about 30% of the time, and larger digits occur as the leading digit with lower and lower frequency, to the point where 9 as a first digit occurs less than 5% of the time. This distribution of first digits is the same as the widths of gridlines on the logarithmic scale.
And from Jialang:
Deviations from Benford’s law have increased substantially over time, such that today the empirical distribution of each digit is about 3 percentage points off from what Benford’s law would predict. The deviation increased sharply between 1982-1986 before leveling off, then zoomed up again from 1998 to 2002. Notably, the deviation from Benford dropped off very slightly in 2003-2004 after the enactment of Sarbanes-Oxley accounting reform act in 2002, but this was very tiny and the deviation resumed its increase up to an all-time peak in 2009.
Looks like recessions are bad for corporate disclosure. Makes sense: if you can make the growth targets, you’re not worried. Once things get ugly, though…
But levels matter here, not rates. Why does it become entrenched?
I would love to find some time to apply this to insurance company data…
Here is some healthy corrective:
Six hours was enough, between the 6 a.m. start time and noon lunch break, for the first wave of local workers to quit. Some simply never came back and gave no reason. Twenty-five of them said specifically, according to farm records, that the work was too hard.
So they go back to collecting unemployment or something? Yikes, that’s crazy-juice for right-leaning voters.
The thing that irritates me about ‘jobs policy’ (what a ridiculous term) is that people are not very concrete about the problem and I like to remind myself sometimes what it’s all about.
First remember that to quiet down voters we need to satisfy several apparently contradicting impulses:
People don’t want to live in rural areas.
People don’t want to do manual labor. People don’t want to work hard generally. That’s not a criticism, mind you. Who wants to be forced to do something unpleasant?
People want a better life than their parents and are happy to wait for it. And live with their parents until it arrives.
“Good jobs” allow people be lazy, urban and rich. Auto workers were the poster-children of this movement, and for good reason.
I grew up in the catchment area for the Motor City Auto industry and I’ll always remember the stories of the Temporary Part Time job contracts some kids of auto workers were granted.
This was stuff that made lazy teenagers salivate: lots of downtime, no skills required, lots of breaks, discounts on cars and $22/hour in 1998 for a 17-year-old. Absolutely outrageous. And the employment practices were no better than the most hideous nepotocracies* on earth. Insiders win.
Anyway, a complete discussion of this should match my criteria above with a picture of who is actually unemployed.

See here too. In order of predictive power, my understanding is that the characteristics go like this: poorly educated, urban, young and dark-skinned. I’m not actually sure this matters, because the unemployed have probably always come from the ranks of the disenfranchised in society.
*I wish I could put that one into the words of the day, but I googled it and found loads of instances. No such thing as a new idea, I suppose.
To my everlasting surprise, somebody made it far enough through some of my course notes to understand what on earth I was going on about.
I was forwarded a link to a real life implementation of xml. Actual examples are always nice to think through the implications of the theory.
But be forewarned, ye hapless Web denizens, this is a discussion not fit for all. Formatting reports for transferring retirement-related employee data among federal agencies. Has quite the ring to it, non?
Here’s the question: why and how do people use these tools?
The purpose of all this nonsense is to get machine readable data into the mothership system. Surely they’re choking on the fedex bills and warehouses of paper files. It’s the friggen 21st century after all.
XML does give you machine readable data. And it has this other benefit: it doesn’t really matter how you create it. Each government agency could format a report out of a sophisticated relational database or pay a legion of underemployed construction workers to handcode a text file. Either works as long as the format checks out.
So XML just plugs into your existing system (even if it’s a system of handwritten forms and carbon copies). Database systems are not quite so forgiving. You need a “new system”, in the most horrible, time/cost draining meaning of the term.
In this case, I’d speculate that the xml format is considered an early first step. It’s hardly feasible to lay the redundant paper-form jockeys off any time soon. Unions will make sure of that. But having a continuous corporate structure holds you back, too.
In more lightly-regulated process-heavy industries, most companies were either acquired or driven out of business before the haggard survivors finally completed their metamorphosis, which is actually never really complete. Google ‘COBOL programming language’ for an taste of the eternal duel against legacy software. And paper files?! Machines barely even read that crap. Try finding (with your computer!) any reliable data collected before 2000 (ie the dawn of machine history). Oh, you found some? Well, hide your grandkids, ’cause that shit was INPUTTED BY HAND!
Anyway, back to Uncle Sam’s pension files. The endgame is obvious: direct API links between the central system and every payroll/HR system in each office. This eliminates costs (jobs) and will improve accuracy. Good stuff.
Until then we’re still building XML files and presumably emailing them around. I can hardly be critical here as I’ve only just started to see the emergence of API links between insurers and reinsurers. No XML schemas, though, because they’re using a type-controlled relational database. Fancy way of saying they keep the data clean at the entry point: pretty hard to soil those databases. As it should be.
To my novice eye the system impresses. Flicking through the documentation suggests they might want to cool off on the initialisms and structured prose as it reads a bit like an engineering manual from the 60s. But engineers they probably are (and targeting an engineering audience to boot), so I’m probably being unfair.
Bless ’em.
Easy: programming. But what does that do for us?
I just read Alan Kay‘s essay: The Computer Revolution Hasn’t Happened Yet. There’s also a video of the lecture on which this essay is based. Haven’t watched it yet.
Here’s the synopsis: when the boys at PARC in the 70s were inventing just about every major component of the personal computer we use today, they had gigantic aspirations. They had a printing press-style revolution in mind and Kay is unimpressed with humanity’s progress using those breakthroughs. He figures we’re still only scratching the surface of its power. I agree.
Here’s how he rationalizes it:
One way to look at the real printing revolution in the 17th and 18th centuries is in the co-evolution in what was argued about and how the argumentation was done.
Increasingly, it was about how the real world was set up, both physically and psychologically, and the argumentation was done more and more by using and extending mathematics, and by trying to shape natural language into more logically connected and less story-like forms.
The point here is:
As McLuhan had pointed out in the 50s, when a new medium comes along it is first rejected on the grounds of “too strange and different”, but then is often gradually accepted if it can take on old familiar content. Years (even centuries) later, the big surprise comes if the medium’s hidden properties cause changes in the way people think and it is revealed as a wolf in sheep’s clothing.
So, the computer is going to literally change the way we think about and solve problems and this hasn’t really happened yet.
Big thought, that one. I like it a lot.
Kay would answer my questions at the beginning of this post as follows, perhaps: computers let us learn programming, which allows us how to simulate stuff, to play with ideas.
He spends quite some time on his work with children learning science by programming computers to test out ideas of their own. To learn the best way one can learn: by failing. Or let’s dust off an old metaphor: the printing press let us learn by watching, the computer allows us to learn by doing.
If this is right, it means that tomorrow’s people will simply have a better intuitive grasp of difficult concepts: they’ll be smarter. Is it crazy to say that a pedagogy with computer games as its centerpiece will revolutionize education and the world? Sure sounds a bit crazy.
Kay laments that our society sees a computer and thinks ‘super-TV’. Ouch, but he’s right. Remember the One Laptop Per Child program? Kay’s affiliated with it, unsurprisingly. When I heard that I had a flashback to some of the commentary: “What on earth will kids do with a cheap computer when they don’t have water? Watch YouTube?” Imagine Kay’s exasperated reply: “they’d learn, you fool!”
Because they aren’t super-televisions. Oh, no.
Computer literacy was once learning to type. Mechanical skills?!How laughably 19th century. More recently it meant learning how to open a document in Windows: pshah, that’s like teaching one book in an English class. Better to teach the kid to write!
You pick up those basic skills as you go along. The point is that we can’t rely on everyone teaching themselves. Computer literacy means literally learning how to read to and from computers. It is learning programming.
And it’s the future.
The question that I don’t have a really good feel for is to what degree the housing market is a canary or millstone. Being only 5% of the economy, one is of course inclined to think of it as a canary.
But here’s the thing: Residential construction companies employ a lot of relatively casual labor. A lot of unskilled labor. A lot of the kind of labor that is, RIGHT NOW, unemployed.
The question then is what the marginal impact of a decline in the housing market might be. One thing’s for sure, anyway. That market is completely effed right now:

In New York we’re noticing some serious signs of the residential and commercial real estate markets recovering (our rent is going up and our expanding office is having some trouble finding a home).
One can take this to mean different things. One interpretation is that there is some serious regional variation contained in these graphs, which appears to have some weight

Another possibility is that I don’t know what I think I know because most data is actually just BS.
The problem with new Keynesian economists is that they believe the government data for inflation, real wages, etc, actually measures the theoretical concepts that the model tries to address. But they don’t. Even NGDP is far from perfect, but at least it’s not as distorted as the CPI.
That’s Scott Sumner defending his use of NGDP because it’s the least BS stat out there. I’m heavily persuaded by this kind of argument. A little while ago, I posted something similar to this and actually got into a comment discussion, which is a rather novel thing for me here.
I feel like educated folks tend to make decisions with the part of their brains they trained in school, the part that’s wired for analysis on a given dataset and coming up with The Right Answer is the challenge.
Big contrast to real life. If you had described my job to me when I was a student, I’d imagine myself slogging through difficult math and trying to figure out how to optimally process a dataset. No so. In fact, I’m not sure I’d really want that job or be anywhere near as good at it as I feel I am at this one.
I actually spend about 75% of my time trying to figure out whether this steaming datapile is in ANY way useful. The analytical part is usually pretty straightforward. It has to be. Heck, the rest of my job is trying to shoehorn this datapile into an analysis everyone can understand instantly.
Clients are distracted, busy people and they’d say my work is important but they are often juggling a lot. My complexity test, therefore, goes like this: can this analysis be explained to a child?
And that’s as it should be. Fancy models have their place, but only when used to support conventional wisdom and gut instinct. Counter-intuitive, Complex and Useful: pick two.
I often get the feeling that macroeconomics in particular is a bit too counter-intuitive for its own good. Practitioners get wrapped up in their models and don’t spend quite enough time understanding exactly what is and is not BS. As a result, they have very weak intuition. I suspect they’d be pretty freaked out if they went down to the sausage factory and had a look.
Michael Mandel again:
Over the past year, jobs in electronic shopping establishments are up 11% (the zigs and zags come from holiday employment). Jobs in “internet publishing, broadcasting and web search portal” establishments are up 20%. Employment in computer systems design, programming and related is up 5%, but that’s off a much larger base (please excuse the funky formatting…my power is still out).
This probably understates the demand for these kinds of jobs, as I would bet that wages are rising faster than average for these kinds of skilled workers.
I wonder, too, at people that are ‘overemployed’ in jobs in which they learn as they go. It isn’t just computer programmers that program computers after all.
I wonder if it would make sense to take a series of jobs whose title and function have largely stayed the same, but in which the application of technology has completely transformed the skills required.
How about school teachers? They’ve been integrating computers into the classroom for years now. Since when did a teacher need to understand that kind of technology?
Since the day that everyone did.
Here is a post on demographics. CalculatedRisk sums it up well:
This is probably another reason many boomers will never retire
I agree with the general sentiment here, but will quibble nonetheless.
The study correlates one-year trailing P/E to the ratio of Middle-Aged over Old People (sounds a bit juvenile putting it that way). They calibrate this relationship and project the P/E ratio over the next few years. I have a few comments

Ok, now I’m pissed off. What on earth are they doing taking the log of the age ratio? What is non-linear about an age ratio? Oh, wait, let me just flick down to the footnotes to find the explanation for this unexpected and important assumption.
[crickets]
What does taking the ln of the age ratio do? Well, luckily they offer up their data and I compared the log data and the ‘raw’ data. Logarithms matter, folks:

Back to #1 above for a sec. Russ Roberts has this fantastic idea that every scientific study should be published with a little appendix showing all of the dead ends and false leads the researchers spun their wheels on.
I wonder how many different ways these researchers crunched this (these!) data before they found a proposition that fit their conclusion. Did they write up the report before they even conducted the analysis?
Anyway, even garbage research can tickle my bias and make me think for a sec. In this case CalculatedRisk has the right tack, which has been expanded upon by WCI. Boomers aren’t retiring.
Great, but yawn. Heard that before.
I’m drawn back to one of the irritating things about that previous analysis. If the boomer retirement party is postponed, what was the reverse effect back in the 90s when they were peaking in productivity?
Back to WCI, for a Canadian take:

Declining employment levels of their elders is the answer. Early retirement. Poor boomers won’t have it as good as those they displaced.
The thing with Tsunamis is that, just before they strike, they suck all of the water off the beach. Then, as we all know about big waves the water pulls back from the force of the retreating water. Boomers can’t help but push their adjacent demographic groups out of the workforce.

{kind=link}